


A Inteligência Artificial (IA) agora faz parte da nossa vida cotidiana. É percebido como “inteligência” e ainda assim depende fundamentalmente de estatísticas. Seus resultados são baseados em padrões de dados previamente aprendidos. Assim que nos afastamos do assunto que aprendemos, nos deparamos com o fato de que não há muita coisa inteligente sobre ele. Uma pergunta simples, como “Desenhe-me um arranha-céu e um trombone deslizante lado a lado para que eu possa apreciar seus respectivos tamanhos” lhe dará algo assim (esta imagem foi gerada por Gemini):

Este exemplo foi gerado pelo modelo do Google, Gemini, mas a IA generativa remonta ao lançamento do ChatGPT em novembro de 2022 e tem, na verdade, apenas três anos. A tecnologia mudou o mundo e não tem precedentes em sua taxa de adoção. Atualmente, 800 milhões de usuários conte com o ChatGPT todas as semanas para realizar diversas tarefas, de acordo com a OpenAI. Observe que o número de solicitações tanques durante as férias escolares. Embora seja difícil obter números precisos, isso mostra como o uso da IA se tornou generalizado. Em volta um em cada dois estudantes usa IA regularmente.
IA: tecnologia essencial ou um artifício?
Três anos são longos e curtos. É longo num campo onde a tecnologia está em constante mudança, e curto quando se trata de impactos sociais. E embora estejamos apenas a começar a compreender como utilizar a IA, o seu lugar na sociedade ainda não foi definido – tal como a imagem da IA na cultura popular ainda não foi estabelecida. Ainda oscilamos entre posições extremas: a IA vai ser mais esperta que os seres humanos ou, pelo contrário, é apenas uma peça inútil de tecnologia brilhante.
Na verdade, um novo apelo à pausa na investigação relacionada com a IA foi emitido em meio a receios de uma IA superinteligente. Outros prometem a terra, com um artigo recente apelando às gerações mais jovens para abandonar completamente o ensino superioralegando que a IA destruiria os diplomas universitários.
As limitações de aprendizagem da IA equivalem à falta de bom senso
Desde que a IA generativa se tornou disponível, venho conduzindo um experimento que consiste em pedir que ela desenhe dois objetos muito diferentes e depois verificar o resultado. O objetivo por trás dessas minhas instruções é ver como o modelo se comporta quando sai de sua zona de aprendizado. Normalmente, isso se parece com um prompt como ‘Desenhe-me uma banana e um porta-aviões lado a lado para que possamos ver a diferença de tamanho entre os dois objetos’. Este prompt usando Mistral fornece o seguinte resultado:
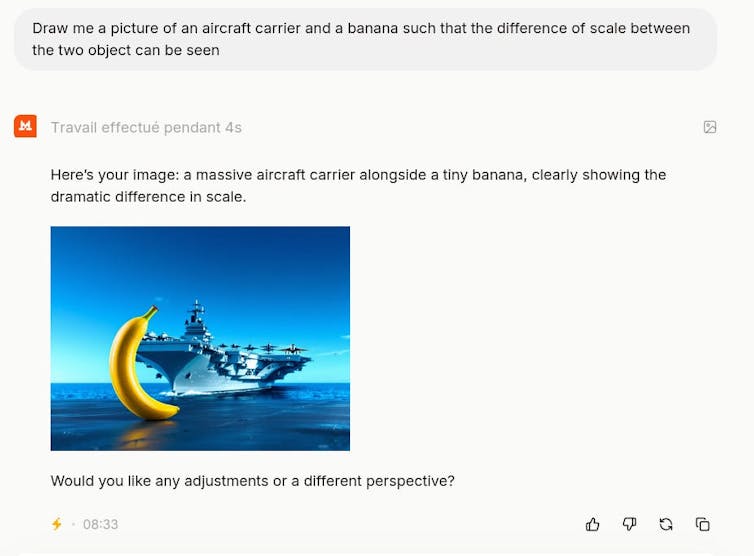
Autor fornecido
Ainda não encontrei um modelo que produza um resultado que faça sentido. A ilustração no início do artigo captura perfeitamente como funciona esse tipo de IA e suas limitações. O facto de se tratar de uma imagem torna os limites do sistema mais tangíveis do que se fosse para gerar um texto longo.
O que chama a atenção é a falta de credibilidade do resultado. Até uma criança de 5 anos seria capaz de dizer que isso não faz sentido. É ainda mais chocante que seja possível ter conversas longas e complexas com as mesmas IAs sem a impressão de estar lidando com uma máquina estúpida. Aliás, essas IAs podem passar no exame da ordem ou interpretar resultados médicos (por exemplo, identificar tumores em uma varredura) com maior precisão do que os profissionais.
Onde está o erro?
A primeira coisa a notar é que é complicado saber exatamente o que está diante de nós. Embora os componentes teóricos da IA sejam bem conhecidos, um projeto como o Gemini – assim como modelos como ChatGPT, Grok, Mistral, Claude, etc. – é muito mais complicado do que um simples Ciclo de Vida de Aprendizado de Máquina (MLL) acoplado a um modelo de difusão.
MML são IAs que foram treinadas em enormes quantidades de texto e geram uma representação estatística dele. Resumindo, a máquina é treinada para adivinhar a palavra que fará mais sentido do ponto de vista estatístico, em resposta a outras palavras (seu prompt).
Os modelos de difusão utilizados para gerar imagens funcionam de acordo com um processo diferente. O processo de difusão é baseado em noções da termodinâmica: você pega uma imagem (ou trilha sonora) e adiciona ruído aleatório (neve na tela) até que a imagem desapareça. Em seguida, você ensina uma rede neuronal a reverter esse processo, apresentando essas imagens na ordem oposta à adição de ruído. Este aspecto aleatório explica porque o mesmo prompt gera imagens diferentes.
Outro ponto a considerar é que esses prompts estão em constante evolução, o que explica porque o mesmo prompt não produzirá os mesmos resultados de um dia para o outro. As alterações podem ser feitas manualmente em casos singulares para responder ao feedback do usuário, por exemplo.
Como médico, simplificarei o problema e considerarei que estamos lidando com um modelo de difusão. Esses modelos são treinados em pares imagem-texto. É, portanto, seguro assumir que os modelos Gemini e Mistral foram treinados em dezenas (ou possivelmente centenas) de milhares de imagens de arranha-céus (ou porta-aviões), por um lado, e numa grande massa de trombones deslizantes, por outro – normalmente, grandes planos de trombones deslizantes. É muito improvável que estes dois objetos sejam representados juntos no material de aprendizagem. Conseqüentemente, o modelo não tem ideia das dimensões relativas desses objetos.
Os modelos carecem de ‘compreensão’
Tais exemplos mostram como os modelos não têm representação interna ou compreensão do mundo. A frase “comparar seus tamanhos” prova que não há compreensão do que é escrito pelas máquinas. Na verdade, os modelos não têm representação interna do significado de “comparar”, a não ser nos textos em que o termo foi utilizado. Assim, qualquer comparação entre conceitos que não aparecem no material de aprendizagem produzirá os mesmos tipos de resultados que as ilustrações apresentadas nos exemplos acima. Será menos visível, mas igualmente ridículo. Por exemplo, esta interação com Gêmeos: ‘Considere esta pergunta simples: “O dia em que os Estados Unidos foram estabelecidos foi um ano bissexto ou um ano normal?”‘
Quando consultado com o prefixo CoT (Chain of Thought, um desenvolvimento recente em LLMs cujo objetivo é decompor uma questão complexa em uma série de subquestões mais simples), o modelo moderno da linguagem Gemini respondeu: “Os Estados Unidos foram estabelecidos em 1776. 1776 é divisível por 4, mas não é um ano de século (100 anos), portanto é um ano bissexto.
É claro que o modelo aplica corretamente a regra do ano bissexto, oferecendo assim uma boa ilustração da técnica CoT, mas tira a conclusão errada na etapa final. Estes modelos não têm uma representação lógica do mundo, mas apenas uma abordagem estatística que cria constantemente estes tipos de falhas que podem parecer “erradas”.
Esta constatação é ainda mais benéfica dado que hoje, AI escreve quase tantos artigos publicados na Internet como seres humanos. Portanto, não se surpreenda se você se surpreender ao ler determinados artigos.

Um e-mail semanal em inglês apresentando conhecimentos de acadêmicos e pesquisadores. Fornece uma introdução à diversidade da investigação proveniente do continente e considera algumas das principais questões enfrentadas pelos países europeus. Receba o boletim informativo!


